主页 > imtoken安卓ico > 以太坊C++源码分析(五)区块链同步(一)
以太坊C++源码分析(五)区块链同步(一)
在 p2p(6) 部分的末尾,我们提到了 BlockChainSync::syncPeer() 函数。 其实这里我们已经进入了另外一个重要的模块:区块链同步模块,它是一个P2P模块交互模块。
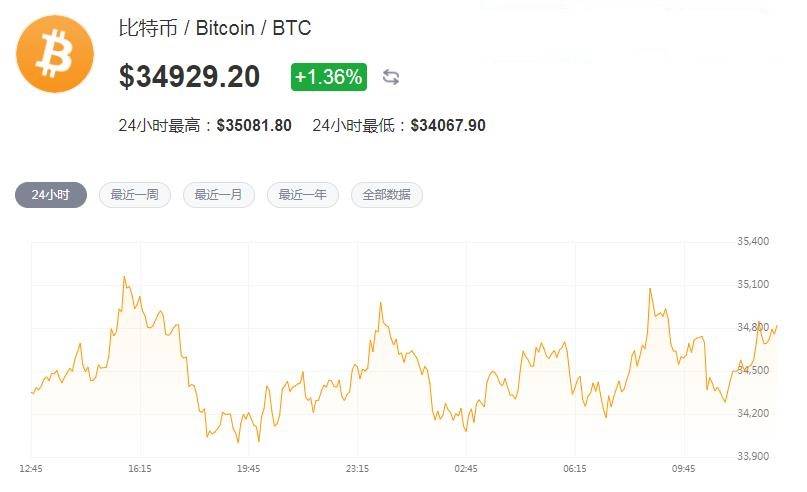
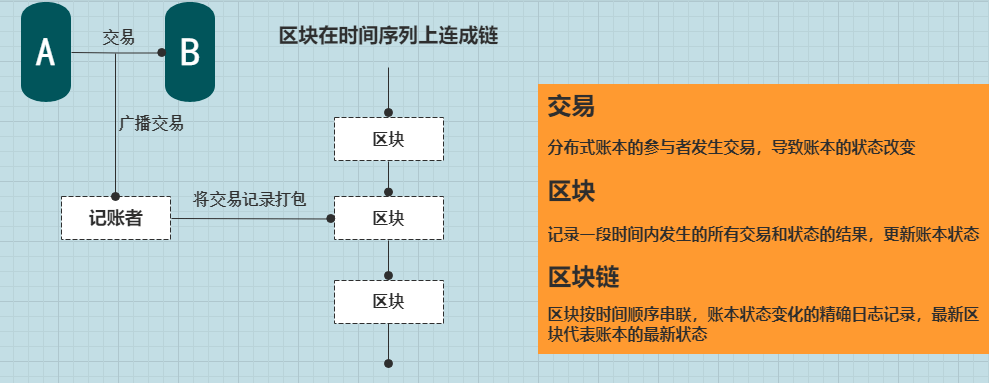
我们知道区块链是一个分布式账本,所有的全节点上都有一份完整的区块链副本,这些全节点之间是相互同步的。 当我们在本地建立一个全节点时,首先需要同步来自其他节点的所有区块。 目前,以太坊主网链拥有超过600万个区块,ropsten测试链拥有超过400万个区块。 具体区域块信息可以在 Etherscan 网站上找到。
如果要在链上发送交易,必须等到本地区块链同步接近最新区块,否则交易不会被广播。 也就是说,区块链同步接近完成是交易发生的先决条件! 这里我们使用close to completion而不是completion,因为区块同步永远不会完成,以太坊会在10秒左右产生一个新的区块。
数百万块的同步是一个非常漫长和痛苦的过程。 我目前正在同步 ropsten 测试链。 可能是链上攻击频繁,可能国内节点少,同步过程比较不稳定,速度很快。 有时候一晚上能同步50万个区块,慢的时候卡在某个区块好几天。
因此,深入了解区块链的同步过程是非常有必要的。
题外话不多说,先从BlockChainSync::syncPeer()函数说起
void BlockChainSync::syncPeer(std::shared_ptr _peer, bool _force)
{
// ...
if (m_state == SyncState::Waiting)
return;
u256 td = host().chain().details().totalDifficulty;
if (host().bq().isActive())
td += host().bq().difficulty();
u256 syncingDifficulty = std::max(m_syncingTotalDifficulty, td);
if (_force || _peer->m_totalDifficulty > syncingDifficulty)
{
if (_peer->m_totalDifficulty > syncingDifficulty)
LOG(m_logger) << "Discovered new highest difficulty";
// start sync
m_syncingTotalDifficulty = _peer->m_totalDifficulty;
if (m_state == SyncState::Idle || m_state == SyncState::NotSynced)
{
LOG(m_loggerInfo) << "Starting full sync";
m_state = SyncState::Blocks;
}
_peer->requestBlockHeaders(_peer->m_latestHash, 1, 0, false);
_peer->m_requireTransactions = true;
return;
}
if (m_state == SyncState::Blocks)
{
requestBlocks(_peer);
return;
}
}
一开始有一个判断条件m_state == SyncState::Waiting,是同步的开关。 从其他节点同步的块放在缓存中。 当缓存满了,开关关闭,同步会暂时停止。
u256 td = host().chain().details().totalDifficulty;
if (host().bq().isActive())
td += host().bq().difficulty();
u256 syncingDifficulty = std::max(m_syncingTotalDifficulty, td);
这段代码是计算本地当前同步的区块链的总难度。
区块链矿工竞争是以难度来衡量的,所有节点都倾向于相信难度更大的区块
如果节点peer的总难度大于我自己的难度,那么就需要从这个节点同步(这里有个漏洞,如果有人伪造了一个很高的难度,那么这个节点会一直从对方同步,直到出现新的难度更大的难度节点,可能会导致同步卡住)
m_state 指示同步状态。 当 m_state 为 SyncState::Idle 或 SyncState::NotSynced 时,同步才真正开始!
区块分为区块头和区块体,分别下载。
首先下载对方节点最新区块的区块头,即:
_peer->requestBlockHeaders(_peer->m_latestHash, 1, 0, false);
EthereumPeer::requestBlockHeaders() 函数在这里被调用。
反之,如果该节点的难度没有我的高,并且之前同步过区块头,则准备同步区块体,即:
if (m_state == SyncState::Blocks)
{
requestBlocks(_peer);
return;
}
我们先看看EthereumPeer::requestBlockHeaders()函数的实现。
EthereumPeer类中有两个requestBlockHeaders()函数,一个是按块号同步以太坊平台开源,另一个是按块哈希值同步,这里调用后者。
void EthereumPeer::requestBlockHeaders(h256 const& _startHash, unsigned _count, unsigned _skip, bool _reverse)
{

// ...
setAsking(Asking::BlockHeaders);
RLPStream s;
prep(s, GetBlockHeadersPacket, 4) << _startHash << _count << _skip << (_reverse ? 1 : 0);
LOG(m_logger) << "Requesting " << _count << " block headers starting from " << _startHash
<< (_reverse ? " in reverse" : "");
m_lastAskedHeaders = _count;
sealAndSend(s);
}
这个函数比较简单,就是发送一个GetBlockHeadersPacket数据包给对方。 那么对方收到这个包裹后是怎么回应的呢? 和往常一样,去EthereumPeer::interpret()函数找到:
case GetBlockHeadersPacket:
{
/// Packet layout:
/// [ block: { P , B_32 }, maxHeaders: P, skip: P, reverse: P in { 0 , 1 } ]
const auto blockId = _r[0];
const auto maxHeaders = _r[1].toInt();
const auto skip = _r[2].toInt();
const auto reverse = _r[3].toInt();
auto numHeadersToSend = maxHeaders <= c_maxHeadersToSend ? static_cast(maxHeaders) : c_maxHeadersToSend;
if (skip > std::numeric_limits::max() - 1)
{
cnetdetails << "Requested block skip is too big: " << skip;
break;
}
pair const rlpAndItemCount = hostData->blockHeaders(blockId, numHeadersToSend, skip, reverse);
RLPStream s;
prep(s, BlockHeadersPacket, rlpAndItemCount.second).appendRaw(rlpAndItemCount.first, rlpAndItemCount.second);
sealAndSend(s);
addRating(0);

break;
}
可以看出,这里的主要功能是调用hostData->blockHeaders()函数获取区块头,回复对方的BlockHeadersPacket数据包。 其中hostData为EthereumHostData类指针,blockId可能有两个值,分别为区块号或区块哈希值,对应前面两个requestBlockHeaders()函数。 maxHeaders 是请求块头的数量。
让我们看一下 EthereumHostData::blockHeaders() 函数的实现:
这个函数有点长,先贴一段代码:
auto numHeadersToSend = _maxHeaders;
auto step = static_cast(_skip) + 1;
assert(step > 0 && "step must not be 0");
h256 blockHash;
if (_blockId.size() == 32) // block id is a hash
{
blockHash = _blockId.toHash();
// ...
if (!m_chain.isKnown(blockHash))
blockHash = {};
else if (!_reverse)
{
auto n = m_chain.number(blockHash);
if (numHeadersToSend == 0)
blockHash = {};
else if (n != 0 || blockHash == m_chain.genesisHash())
{
auto top = n + uint64_t(step) * numHeadersToSend - 1;
auto lastBlock = m_chain.number();
if (top > lastBlock)
{
numHeadersToSend = (lastBlock - n) / step + 1;
top = n + step * (numHeadersToSend - 1);
}
assert(top <= lastBlock && "invalid top block calculated");
blockHash = m_chain.numberHash(static_cast(top)); // override start block hash with the hash of the top block we have
}
else
blockHash = {};
}
}
numHeadersToSend的值为需要发送的最大块头数,_skip的值为0,所以step的值为1。
然后判断_blockId是区块hash还是区块号。 这里贴出的代码是区块哈希,处理区块号的代码类似。 有兴趣的可以自己查一下。
if (!m_chain.isKnown(blockHash))
blockHash = {};
这里是判断如果块哈希不在我本地的区块链中,什么都不会返回。
_reverse值为false,取出blockHash对应的块号n,计算要取出的最高块号top,然后得到当前区块链的最新块号lastBlock,判断边界条件,top值不能超过lastBlock,如果超过则top=lastBlock,然后计算top对应的区块哈希值blockHash。
注意这里的blockHash是最高块的hash值,为什么要这个值呢? 因为区块链中的区块是像单向链表一样连接起来的,其中第0个区块是创建区块,后面的区块都是从1开始递增的,每个区块都会记录前一个区块的哈希值,相当于指向父块的指针,所以我们在遍历时只能从后往前遍历。

区块链图
然后往下看:
auto nextHash = [this](h256 _h, unsigned _step)
{
static const unsigned c_blockNumberUsageLimit = 1000;
const auto lastBlock = m_chain.number();
const auto limitBlock = lastBlock > c_blockNumberUsageLimit ? lastBlock - c_blockNumberUsageLimit : 0; // find the number of the block below which we don't expect BC changes.
while (_step) // parent hash traversal
{
auto details = m_chain.details(_h);
if (details.number < limitBlock)
break; // stop using parent hash traversal, fallback to using block numbers
_h = details.parent;
--_step;
}
if (_step) // still need lower block
{
auto n = m_chain.number(_h);
if (n >= _step)
_h = m_chain.numberHash(n - _step);
else
_h = {};
}
return _h;
};
这里定义了一个函数nextHash(),用于从后向前遍历区块hash。 _h为当前区块的哈希,_step的值为1。
可以看出块被分割和分化了。 如果_h所在区块距离最新区块超过1000个区块以太坊平台开源,则区块号递减进行遍历,也就是遍历数组的方式进行遍历,即_h = m_chain.numberHash(n - _step );,否则按单向链表的方式遍历,即_h = details.parent;。
最后一部分准备返回数据
bytes rlp;
unsigned itemCount = 0;
vector hashes;
for (unsigned i = 0; i != numHeadersToSend; ++i)
{
if (!blockHash || !m_chain.isKnown(blockHash))
break;
hashes.push_back(blockHash);
++itemCount;
blockHash = nextHash(blockHash, step);
}
for (unsigned i = 0; i < hashes.size() && rlp.size() < c_maxPayload; ++i)
rlp += m_chain.headerData(hashes[_reverse ? i : hashes.size() - 1 - i]);
return make_pair(rlp, itemCount);
将需要返回的区块头放入rlp中,统计返回的区块头的itemCount个数。
从这里可以看出,有时itemCount为0,即无法返回区块头,这种情况在实际同步中经常遇到。